Why the future of Pharma data can only be FAIR

FAIR data is a defining component for a future-proofed pharma or life science enterprise. But what is FAIR data, and how can data be made FAIR? We explain how knowledge graphs achieve FAIR data to accelerate discovery, overcome regulatory hurdles, and supercharge AI you can trust.
The data foundation for natural law models
While the industry fixates on compute power, the real bottleneck for AI in Pharma remains the data itself. In this article, Mark Hahnel, VP of Open Research at Digital Science, explores why FAIR principles and Knowledge Graphs are the "binding constraints" for the future of scientific AI.
Smarter Digital Twins with metaphactory: AI, Knowledge Graphs and Asset Administration Shell for Industry 4.0

Discover how the Asset Administration Shell (AAS) and metaphactory transform industrial data exchange. This post explores how knowledge graphs and AI enhance AAS for interoperable digital twins and compliance with regulations like the Digital Product Passport (DPP).
Transparent federation with FedX - Solving challenges with new optimization techniques

Discover how transparent federation in metaphactory enables a unified view across distributed knowledge graphs, addressing challenges like data silos and compliance. Principal Engineer Andreas Schwarte discusses its evolution, optimization and real-world applications.
Efficient and high-performance operation of semantic models in Enterprise Information Architecture

In this guest post, Michael Schäfer, IT architect and Division Lead Multicloud & Modern Work at Netlution dives into how semantic knowledge models enable efficient data collection, organization, and utilization to drive business success, as well as important considerations when assessing the IT operating model for an EIA solution.
Building massive knowledge graphs using automated ETL pipelines
 In this blog post, we’ll explore how to build a massive knowledge graph from existing information or external sources in a repeatable and scalable manner. We’ll go through the process step-by-step, and discuss how the Graph-Massivizer project supports the development of multiple large knowledge graphs and the considerations you need to take when creating your own graph. Keep reading!
In this blog post, we’ll explore how to build a massive knowledge graph from existing information or external sources in a repeatable and scalable manner. We’ll go through the process step-by-step, and discuss how the Graph-Massivizer project supports the development of multiple large knowledge graphs and the considerations you need to take when creating your own graph. Keep reading!
Fragmented knowledge in pharma: Bridging the divide between private and public data

This post has also been published on the Digital Science TL;DR website.
Despite the increasing availability of public data, why are so many pharma and life sciences organizations still grappling with a persistent knowledge divide? This discrepancy was a focal point at the recent BioTechX conference in October, Europe's largest biotechnology congress that brings together researchers and leaders in pharma, academia and business. In this post, we explore the need to connect data from different sources and all internal corporate data through one, integrated semantic data layer.
An Interconnected System for Reference Data

Publishing FAIR data in the humanities sector
Reference data is a crucial element of data curation in the cultural heritage and humanities sector. Using reference data brings multiple benefits, such as consistent cataloguing, easier lookup and interaction with the data, or compatibility with other data collections that use the same reference data. Overall, the use of reference data can support the publication of FAIR data - data that is findable, accessible, interoperable and reusable.
In museum collection management, for example, various thesauri can be used as reference data to ensure the accurate and consistent cataloguing of items in a controlled manner and according to specific terminologies. Thesauri exist for various areas of expertise. One example is the Getty Art and Architecture Thesaurus® (AAT) which describes the different types of items of art, architecture and material culture, such as "cathedral" as a type of religious building. Authority data has also been published to support the unique identification of specific entities such as persons, organizations, or places, for example, "Cologne cathedral" as a specific instance of the type "cathedral". Such authority data sources include The Integrated Authority File (GND) or the Union List of Artist Names® Online (ULAN) and are specifically important for disambiguating over entities with the same name, e.g., Boston, the town in the UK, and Boston, the city in the USA.
Digital humanities projects often combine several research directions and use materials that cover multiple disciplinary areas. This makes the implementation of reference data difficult, as several reference data sources need to be used to cover all aspects and facets of a project. Moreover, technical access to reference data is inconsistent, with systems using different interfaces and APIs, which makes integration challenging.
The game plan for your Knowledge Graph-driven FAIR Data platform in Life Sciences and Pharma
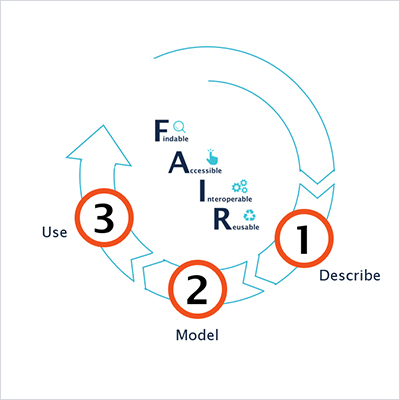
At metaphacts we help customers leverage knowledge graphs to unlock the value of their data assets and drive digital transformation. We started out with this mission in 2014 and, since then, we've served a multitude of customers in pharma and life sciences, engineering and manufacturing, finance and insurance, as well as digital humanities and cultural heritage.
This blog post will give you an overview of what we have developed in customer projects over the years as our game plan to build a Knowledge Graph-driven, FAIR Data platform and drive digital transformation with data. The post will show you how our product metaphactory can support you every step of the way, and will highlight examples from the life sciences and pharma domains.